
0. 강의링크
•
강의 검수 후 추가예정
1. Intro
1.0 강사소개

•
(현) GS 그룹 AX 부트캠프 교육 담당
•
(전) 시리즈 C 인공지능 스타트업 테크리드
◦
1인 개발자 (Seed) → 개발팀 리드 (Series C)
1.1 강의 커리큘럼 소개
2. LangGraph 공식문서를 응용한 LLM Workflow
2.1 LangChain vs LangGraph (feat. LangGraph 개념 설명)
•
가상 환경 설정 및 API 키 관리
◦
Pyenv, Conda, Virtualenv 등 편리한 패키지를 사용하여 가상 환경 관리.
◦
.env 파일에 OpenAI API 키와 같은 환경 변수를 저장.
◦
python-dotenv 패키지를 설치하여 환경 변수를 코드에서 쉽게 호출.
•
LangChain과 LangGraph 비교
◦
LangChain: 순차적인 워크플로우로 구성.
▪
예: 항상 Rewrite를 호출하여 질문을 수정.
◦
Langraph: 조건부 엣지(Conditional Edge)를 활용하여 효율적인 워크플로우 구성.
▪
필요할 때만 Rewrite를 호출하여 LLM 호출 횟수를 줄임.
•
LangGraph의 주요 개념
◦
State: 현재 에이전트의 상태를 관리.
▪
예: 메시지, 검색된 문서, 사용자 질문 등을 포함.
◦
Node: 에이전트가 수행하는 작업.
▪
예: Retrieve, Generate, Rewrite 등.
◦
Edge: 노드 간의 연결을 나타냄.
▪
항상 다음 노드로 이동.
◦
Conditional Edge: 조건에 따라 다음 노드를 선택.
▪
예: 검색 결과가 적절하면 Generate로 이동, 그렇지 않으면 Rewrite로 이동.
•
LangGraph 에이전트 생성 과정
◦
State 선언
▪
TypedDict를 사용하여 메시지와 상태를 관리.
▪
OpenAI의 메시지 형식(SystemMessage, HumanMessage, AIMessage)을 포함.
◦
GraphBuilder 생성
▪
노드와 엣지를 추가하여 그래프를 구성.
◦
Node 생성
▪
예: Generate 노드 생성.
▪
LLM 호출을 통해 사용자 질문에 대한 답변 생성.
◦
Edge 추가
▪
Start와 End 엣지를 추가하여 워크플로우 시작과 종료를 정의.
◦
그래프 컴파일 및 시각화
▪
Mermaid를 사용하여 그래프 구조를 시각적으로 확인.
•
LangGraph의 장점
◦
조건부 엣지를 활용하여 효율적인 워크플로우 구현.
◦
복잡한 멀티 에이전트 시스템 구축 가능.
◦
필요할 때만 LLM 호출로 비용 절감.
•
주의사항 및 팁
◦
간단한 LLM 호출만 필요한 경우 LangGraph는 과도한 설계(Over-engineering)가 될 수 있음.
◦
복잡한 워크플로우나 확장 가능한 시스템이 필요한 경우 LangGraph 사용 추천.
◦
LangGraph의 개념이 처음에는 어려울 수 있으나, 다양한 사례를 통해 이해도를 높일 수 있음.
2.2 간단한 Retrieval 에이전트 (feat. PDF 전처리 꿀팁)
•
복잡한 LangGraph 에이전트 개요
◦
이번 강의에서는 Retriever와 Generator를 추가하여 문서를 기반으로 답변을 생성하는 LangGraph 에이전트를 구현.
◦
사용자가 질문을 하면 관련 문서를 검색하고, 해당 문서를 기반으로 LLM이 답변을 생성.
◦
문서 처리를 통해 더 정확하고 맥락에 맞는 답변 제공.
•
문서 처리 및 RAG 생성
1.
문서 로드 및 분할
•
PDF 문서를 로드하고 페이지 단위로 분할.
•
PDF의 이미지 데이터(예: 표)는 기본 PDF 로더로 처리 불가.
•
OCR 도구(py-zerox)를 사용하여 이미지 데이터를 텍스트로 변환.
2.
Markdown 및 Text 변환
•
OCR로 변환된 데이터를 Markdown 형식으로 저장.
•
Markdown 데이터를 텍스트로 변환하여 정확한 문맥 전달.
3.
벡터 스토어 생성
•
Chroma를 사용하여 문서를 벡터화하고 로컬에 저장.
•
Retriever를 통해 벡터화된 문서를 검색 가능.
•
LangGraph 에이전트 구현 과정
1.
State 정의
•
사용자 질문, 검색된 문서(context), 생성된 답변(answer)을 포함.
2.
Retriever 노드 생성
•
사용자의 질문을 기반으로 벡터 스토어에서 관련 문서를 검색.
•
검색된 문서를 context에 저장.
3.
Generator 노드 생성
•
검색된 문서를 기반으로 LLM이 답변 생성.
•
LangSmith에서 제공하는 프롬프트를 활용하여 효율적인 답변 생성.
•
LLM 호출 시 사용자 질문과 검색된 문서를 함께 전달.
4.
그래프 빌더 생성 및 연결
•
노드: Start → Retrieve → Generate → End.
•
엣지: 노드 간의 순차적 연결.
•
시각화를 통해 그래프 구조 확인.
•
예제 시나리오
1.
질문: "연봉 5천만 원의 소득세는 얼마인가?"
•
Retrieve: 관련 문서(소득세율표 등)를 검색.
•
Generate: 검색된 문서를 기반으로 답변 생성.
2.
문서 검색 실패 시
•
검색된 문서가 부족하거나 부정확한 경우, 질문을 재작성하여 다시 검색.
•
Conditional Edge를 활용하여 효율적인 워크플로우 구현 예정(다음 강의).
•
문서 처리 도구 및 팁
◦
PDF 로더: 텍스트 데이터는 잘 처리하지만 이미지 데이터는 처리 불가.
◦
OCR(py-zerox): PDF의 이미지 데이터를 텍스트로 변환.
◦
Markdown Loader: Markdown 데이터를 로드 및 분할.
◦
Text Loader: 텍스트 데이터를 로드하여 정확한 문맥 전달.
◦
Chroma: 벡터 스토어 생성 및 문서 검색.
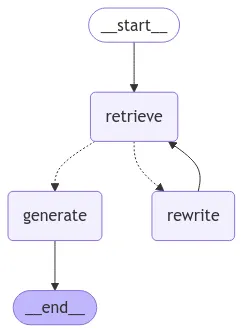
2.3 공식문서 따라하면 실패하는 Agentic RAG
•
워크플로우 개요
◦
사용자의 질문을 받아 문서를 검색(retrieve).
◦
검색된 문서가 질문과 관련이 있는지 검증(check_doc_relevance).
◦
문서가 관련이 있으면 답변을 생성(generate).
◦
문서가 관련이 없으면 질문을 수정(rewrite)하고 다시 검색.
•
노드(Node) 설계
◦
Retrieve: 사용자의 질문을 기반으로 문서를 검색.
◦
CheckDocRelevance: 검색된 문서와 질문의 관련성을 검증.
▪
관련성이 있으면 Generate로 이동.
▪
관련성이 없으면 Rewrite로 이동.
◦
Generate: 질문에 대한 답변 생성.
◦
Rewrite: 질문을 수정하여 검색 결과를 개선.
•
프롬프트 구성
◦
Generate Prompt: 답변 생성을 위한 프롬프트.
◦
Relevance Prompt: 문서와 질문의 관련성을 평가하는 프롬프트.
◦
Rewrite Prompt: 질문을 수정하기 위한 프롬프트.
•
조건부 엣지(Conditional Edge) 구성
◦
Retrieve → CheckDocRelevance: 문서와 질문의 관련성을 검증.
◦
CheckDocRelevance → Generate: 문서가 관련이 있을 경우 답변 생성.
◦
CheckDocRelevance → Rewrite: 문서가 관련이 없을 경우 질문 수정.
◦
Rewrite → Retrieve: 수정된 질문으로 다시 문서 검색.
◦
Generate → End: 답변 생성 후 종료.
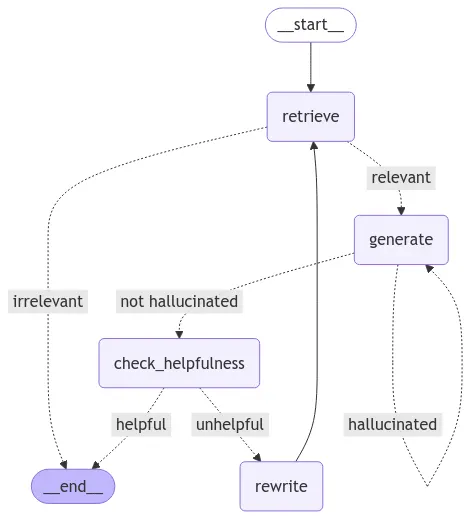
2.4 생성된 답변을 여러번 검증하는 Self-RAG
•
Self-RAG의 개념
◦
에이전트가 스스로를 검증하며 답변의 품질을 향상.
◦
문서를 검색하고, 문서와 질문의 관련성을 확인.
◦
생성된 답변이 문서에 기반했는지 검증.
◦
답변이 질문과 관련이 없거나 환각(Hallucination)이 발생하면 답변을 재생성.
•
Self-RAG의 워크플로우
◦
문서 검색(Retrieve) 후 관련성 확인.
▪
관련성이 없으면 종료.
▪
관련성이 있으면 답변 생성.
◦
생성된 답변에서 환각 여부 확인.
▪
환각이 발생하면 답변 재생성.
▪
환각이 없으면 질문과 답변의 관련성 확인.
◦
질문과 답변이 관련이 없으면 문서를 다시 검색하고 반복.
•
노드(Node) 설계
◦
Retrieve: 문서를 검색.
◦
Generate: 질문에 대한 답변 생성.
◦
Check Relevance: 문서와 질문의 관련성 확인.
◦
Check Hallucination: 생성된 답변의 환각 여부 확인.
◦
Check Helpfulness: 질문과 답변의 관련성 확인.
◦
Rewrite: 문서를 다시 검색하고 답변 재생성.
•
조건부 엣지(Conditional Edge) 구성
◦
Retrieve → Check Relevance: 문서와 질문의 관련성 확인.
▪
관련성이 없으면 종료.
▪
관련성이 있으면 Generate로 이동.
◦
Generate → Check Hallucination: 생성된 답변의 환각 여부 확인.
▪
환각이 있으면 Generate로 다시 이동.
▪
환각이 없으면 Check Helpfulness로 이동.
◦
Check Helpfulness → Rewrite: 질문과 답변의 관련성 확인.
▪
관련이 없으면 Rewrite로 이동.
▪
관련이 있으면 종료.
•
프롬프트 수정 및 최적화
◦
LangChain에서 제공하는 기본 프롬프트를 수정하여 더 정확한 결과 도출.
◦
환각 검증 프롬프트를 간단하고 명확하게 작성.
◦
LLM의 max tokens와 temperature 값을 조정하여 일관된 결과 생성.
2.5 웹 검색을 지원하는 Corrective RAG
•
Corrective RAG 워크플로우:
◦
문서 검색 후 관련성 평가.
◦
관련성이 있으면 답변 생성, 없으면 질문 재작성 및 웹 검색 수행.
•
기존과의 차이점:
◦
기존 재작성은 문서 검색에 초점, 새로운 재작성은 웹 검색에 초점.
•
구현 과정:
◦
Tavilli API 키 설정 및 환경 변수로 관리.
◦
Retrieve, Generate, Relevance 노드 구성 및 Conditional Edge 추가.
◦
웹 검색 결과를 활용하여 답변 생성.
•
최적화 및 성능 개선:
◦
재작성 단계를 생략하면 속도와 비용 절감 가능.
◦
OpenAI API의 캐시 기능을 활용하여 유사 질문에 대한 빠른 응답 제공.
•
실용성 검토:
◦
재작성 단계가 정말 필요한지 검토.
◦
서비스 관점에서 불필요한 재작성 단계 제거로 효율성 증대.
2.6 SubGraph: LangGraph Agent를 Node로 활용하는 방법
•
서브그래프(Sub-Graph)란?
◦
정의:
▪
서브그래프는 하나의 그래프 내에 다른 그래프를 포함하는 구조.
▪
노드처럼 동작하며, 특정 작업을 수행하는 별도의 에이전트를 호출 가능.
◦
사용 목적:
▪
복잡한 로직을 분리하여 재사용성과 모듈화를 높임.
▪
예: 사용자 질문을 분석하여 적절한 서브그래프를 호출하는 "라우터" 노드.
•
Adaptive Logic 구조
◦
질문 분석 및 분기:
▪
라우터(Router)를 통해 질문을 분석하고 적합한 그래프 또는 노드로 라우팅.
◦
3가지 분기:
1.
VectorStore: 질문이 벡터 스토어 데이터와 관련 있는 경우.
2.
LLM: 간단한 질문으로 LLM 데이터만으로 답변 가능한 경우.
3.
Web Search: 복잡한 질문으로 웹 검색이 필요한 경우.
◦
서브그래프 활용:
▪
VectorStore 관련 작업:
•
벡터 스토어에서 정보를 검색하고, 답변의 관련성과 환각 여부를 검증.
▪
Web Search:
•
웹 검색 도구를 통해 정보를 수집하고 GPT-4/5와 같은 고급 모델로 답변 생성.
▪
LLM 단순 호출:
•
간단한 질문에 대해 비용 절감을 위해 작은 모델(예: GPT-mini) 사용.
•
구현 단계
◦
노드와 상태(state) 정의:
▪
상태:
•
사용자 질문(query) 및 결과를 저장.
•
웹 검색 결과는 리스트 형식으로 저장.
▪
노드:
•
라우터, VectorStore 처리, Web Search 처리, LLM 단순 호출 등.
◦
라우터(Router) 구현:
▪
역할:
•
질문을 분석하여 적합한 그래프(또는 노드)로 라우팅.
▪
구현 방식:
•
ChatPromptTemplate를 사용하여 LLM으로 질문을 분석.
•
분석 결과를 Structured Output 형태로 반환하여 라우팅 수행.
◦
서브그래프 등록:
▪
VectorStore 작업을 처리하는 그래프를 서브그래프로 등록.
▪
Python 파일로 서브그래프를 저장 및 가져와 메인 그래프에 추가.
◦
엣지(Edge) 연결:
▪
라우터 결과에 따라 적절한 노드(VectorStore, Web Search, LLM)로 분기.
▪
각 노드의 결과를 최종 응답으로 연결.
2.7 병렬 처리를 통한 효율 개선 (feat. 프롬프트 엔지니어링)
•
LangGraph를 활용하여 병렬 처리 및 정렬(Sorting) 기능을 가진 에이전트를 설계
◦
특정 작업 완료 후 병렬로 작업을 수행하고, 결과를 통합하여 다음 작업 진행
◦
병렬 처리를 통해 작업 속도 향상 및 결과 통합의 효율성 증대
•
종합부동산세 계산 에이전트 설계 및 구현
◦
사용자 질문에서 필요한 정보를 추출
◦
공시가격은 벡터 스토어(Vector Store)에서 검색
◦
시가표준액 비율은 웹 검색(Web Search)을 통해 수집
◦
공시가격과 시가표준액 비율을 조합하여 과세표준 계산
◦
과세표준을 기반으로 최종 세율 계산
•
그래프 구성 및 병렬 처리
◦
노드(Node) 생성: 공시가격 검색, 시가표준액 비율 검색, 과세표준 계산, 세율 계산
◦
노드 간의 엣지(Edge)를 연결하여 작업 흐름 정의
◦
공시가격 검색과 시가표준액 비율 검색을 병렬로 수행
◦
병렬 작업 후 결과를 통합하여 과세표준 계산
•
멀티 에이전트 시스템 구축 및 테스트
◦
종합부동산세 에이전트와 소득세 에이전트를 통합하여 협력적으로 작업 수행
◦
사용자 질문에 따라 공시가격과 시가표준액 비율을 병렬로 검색
◦
검색 결과를 기반으로 과세표준 및 최종 세율 계산
◦
각 노드의 출력이 올바르게 연결되고, 최종 결과가 정확히 계산되는지 확인
2.8 Multi-Agent 시스템과 RouteLLM
•
멀티 에이전트 시스템 개요
◦
여러 에이전트를 하나의 워크플로우에 통합하여 다양한 질문에 대응.
◦
라우터(Router)를 사용하여 사용자의 질문을 적절한 에이전트로 라우팅.
◦
각 에이전트는 특정 목적(예: 소득세, 종합부동산세)에 맞게 설계.
◦
일반적인 질문은 별도의 LLM 에이전트를 통해 처리.
•
멀티 에이전트 시스템 구현 과정
1.
에이전트 내보내기
•
소득세 에이전트와 종합부동산세 에이전트를 Python 스크립트로 내보냄.
•
테스트 및 시각화 코드를 제거하여 간결화.
2.
라우터 생성
•
Adaptive RAG에서 사용한 라우터를 복사하여 수정.
•
소득세와 종합부동산세 에이전트를 라우터에 연결.
•
일반적인 질문은 별도의 LLM 에이전트로 처리.
3.
노드 및 엣지 추가
•
내보낸 에이전트를 노드로 추가.
•
라우터는 Conditional Edge를 통해 질문을 적절한 에이전트로 라우팅.
•
시작(Start)과 종료(End) 엣지를 추가하여 워크플로우 완성.
4.
그래프 시각화 및 실행
•
그래프를 시각화하여 라우팅 구조 확인.
•
질문에 따라 라우터가 적절한 에이전트를 호출.
•
예제 시나리오
1.
소득세 관련 질문
•
예: "연봉 5천만 원의 소득세는 얼마인가?"
•
라우터가 소득세 에이전트로 라우팅.
•
소득세 에이전트가 답변 생성.
2.
종합부동산세 관련 질문
•
예: "공시가격 10억 원의 종합부동산세는 얼마인가?"
•
라우터가 종합부동산세 에이전트로 라우팅.
•
종합부동산세 에이전트가 답변 생성.
3.
일반적인 질문
•
예: "떡볶이를 먹기 좋은 곳은 어디인가?"
•
라우터가 일반 LLM 에이전트로 라우팅.
•
LLM 에이전트가 답변 생성.
3. LangGraph 120% 활용방법
3.1 Workflow vs "찐" Agent
•
LangGraph 에이전트와 워크플로우:
◦
LangGraph에서 개발된 에이전트는 LLM이 "Yes" 또는 "No"로만 판단을 내리고, 실제 행동은 개발자가 미리 정의한 워크플로우에 의해 결정됨.
◦
이는 Anthropic이 정의한 "진정한 에이전트"와 대비되며, LangGraph의 시스템은 워크플로우에 가까움.
•
Anthropic의 에이전트 정의:
◦
Anthropic은 에이전트를 "스스로 다음 단계를 판단하고 문제를 해결하는 시스템"으로 정의.
◦
진정한 에이전트는 스스로 정보를 검증하며, 필요 시 반복적으로 답변을 수정하거나 재작성함.
•
LLM의 역할:
◦
LangGraph에서는 LLM이 특정 도구를 호출하거나, 데이터를 검색하거나, 메타데이터를 분석하는 등 도구 선택과 작업 수행에 도움을 줌.
◦
최근에는 "Function Calling"에서 "Tool Calling" 개념으로 전환됨.
•
LangGraph의 강점:
◦
다양한 LLM과의 연결 가능성(GPT, Amazon Bedrock 등).
◦
무료로 제공되어 개발자에게 높은 커스터마이징 자유도 제공.
◦
워크플로우 기반 시스템을 통해 특정 작업을 더 빠르고 효율적으로 수행 가능.
•
개발 프로세스:
◦
노드와 엣지를 연결해 워크플로우를 구성.
◦
기본 제공 도구 및 사용자 정의 도구를 활용해 에이전트를 설계.
◦
프롬프트를 직접 작성하기보다 도구를 최대한 활용해 실제 에이전트를 구현.
3.2 LangChain에서 도구(tool) 활용 방법
•
도구 정의:
◦
도구는 Python 함수에 스키마(이름, 설명, 인자)를 추가한 형태.
◦
함수에 @tool 데코레이터를 붙여 도구로 변환.
◦
도구는 LLM이 사용할 수 있도록 명시적으로 정의해야 함.
•
도구 호출:
◦
도구는 일반 함수처럼 호출할 수 없고, invoke 메서드를 사용해야 함.
◦
LLM에 도구를 사용 가능하도록 bindTools 메서드를 사용해 도구 리스트를 바인딩.
•
LLM과 도구 상호작용:
◦
LLM이 사용자 질문에 대해 도구 호출이 필요한 경우, tool calls라는 정보가 AI 메시지로 반환됨.
◦
도구 호출 결과를 다시 메시지 리스트에 추가하여 LLM이 응답을 생성.
•
메시지 관리:
◦
LangChain에서는 메시지를 다음 순서로 전달:
▪
HumanMessage → AIMessage → ToolMessage → 결과 반환.
◦
LLM이 도구와의 상호작용을 정상적으로 수행하려면 메시지 히스토리를 올바르게 관리해야 함.
3.3 LangGraph에서 도구(tool) 활용 방법
•
LangChain과 LangGraph의 도구 사용 차이점:
◦
LAngChain:
▪
도구와 LLM을 바인딩.
▪
메시지 리스트를 기반으로 AI 메시지와 도구 호출을 관리.
◦
LangGraph:
▪
도구 노드(tool node)를 제공하여 간단하게 도구 사용 가능.
▪
메시지 상태(message state)를 활용하여 메시지 추가를 자동화.
•
도구 노드(tool node) 작동 방식:
◦
도구 리스트를 선언하고, 이를 도구 노드에 추가.
◦
도구 호출 시 메시지 리스트를 전달하여 작업 수행.
◦
결과 메시지를 메시지 리스트에 추가하여 LLM이 이를 기반으로 응답 생성.
•
에이전트 구성 단계:
◦
상태(state) 선언:
▪
메시지 리스트를 관리하기 위해 메시지 상태(message state)를 사용.
▪
메시지 추가는 add_messages 메서드를 통해 자동 처리.
◦
노드(node) 생성:
▪
에이전트 노드: LLM과 도구 호출을 처리.
▪
도구 노드: 도구를 호출하고 결과를 반환.
▪
조건 노드(should continue): 추가 정보가 필요한지 판단.
◦
엣지(edge) 연결:
▪
노드 간의 흐름을 연결하여 작업 프로세스 구성.
•
작업 흐름(Flow):
◦
사용자 질문 → 에이전트 노드에서 LLM 호출.
◦
LLM이 도구 호출 필요 여부 판단:
▪
도구 호출 필요 시 → 도구 노드로 이동.
▪
필요하지 않을 시 → 종료.
◦
도구 노드가 결과 반환 → 에이전트 노드로 전달.
◦
반복 후 충분한 정보가 수집되면 종료.
•
LangGraph의 장점:
◦
메시지 관리와 도구 호출 과정이 자동화되어 개발이 용이.
◦
내장 도구(예: Google Search, Bing Search, 이메일 도구 등) 활용 가능.
◦
다양한 도구를 혼합하여 복잡한 에이전트 구성 가능.
3.4 LangGraph 내장 도구(tool)를 활용해서 만드는 Agent
•
다양한 LangChain 도구 활용
◦
LangChain에서 제공하는 다양한 도구를 에이전트에 추가하여 기능 확장.
◦
예: DuckDuckGo, Gmail Toolkit, Archive API, Retriever Tool 등.
◦
DuckDuckGo: 무료로 사용할 수 있는 검색 도구.
◦
Gmail Toolkit: 이메일 작성, 전송, 검색 등 다양한 이메일 작업 가능.
◦
Archive API: 논문 요약 및 검색 기능 제공.
◦
Retriever Tool: 검색 및 정보 추출을 간소화.
•
DuckDuckGo 도구 사용
◦
DuckDuckGo는 API 키 없이 무료로 사용 가능.
◦
예제: "오바마가 태어난 도시의 화폐 단위는 무엇인가?"
▪
검색 도구를 통해 출생지를 찾고, 해당 지역의 화폐 단위를 반환.
◦
기존 워크플로우와 비교:
▪
기존에는 프롬프트 작성, 정보 나열, 결과 집계 등 복잡한 과정 필요.
▪
DuckDuckGo 도구를 사용하면 단일 검색으로 간단히 해결.
•
Gmail Toolkit 활용
◦
Gmail API를 통해 이메일 작성 및 전송 가능.
◦
Gmail Credential과 Token 파일을 설정하여 인증.
◦
예제: 검색 결과를 이메일로 전송.
▪
"빌리 자일스가 태어난 곳의 화폐 단위를 찾아 이메일로 보내기."
▪
검색 후 결과를 이메일로 전송.
◦
주의사항: Gmail API 사용 시 권한 설정 및 앱 승인 필요.
•
arXiv API 도구 사용
◦
논문 검색 및 요약 기능 제공.
◦
예제: "논문 요약 요청."
▪
Archive API를 통해 논문을 검색하고 요약.
▪
GPT-4와 같은 더 큰 LLM을 사용하여 고품질 요약 생성.
•
Retriever Tool 활용
◦
복잡한 검색 및 정보 추출 과정을 간소화.
◦
기존 워크플로우에서 여러 노드로 나뉘었던 작업을 단일 도구로 처리.
◦
예제: 종합부동산세 계산.
▪
공시가격, 시가표준액 비율, 과세표준 계산을 단일 Retriever로 처리.
•
Tool Condition 활용
◦
조건부 엣지 대신 Tool Condition을 사용하여 워크플로우 간소화.
◦
기존의 should_continue를 대체하여 더 직관적인 조건 설정 가능.
3.5 Agent의 히스토리를 관리하는 방법
•
에이전트의 채팅 히스토리 관리 개요
◦
에이전트와의 대화 기록을 효율적으로 관리하여 비용 절감 및 성능 최적화.
◦
Checkpoint를 사용하여 상태를 스냅샷으로 저장.
◦
불필요한 메시지를 삭제하거나 요약(Summarize)하여 토큰 사용량 감소.
•
히스토리 관리 구현 과정
1.
Checkpoint 추가
•
MemorySaver 클래스를 사용하여 히스토리 관리.
•
에이전트의 상태를 스냅샷으로 저장하여 대화 흐름 유지.
2.
스레드 관리
•
configurable을 사용하여 스레드 ID를 설정.
•
대화의 특정 스레드를 관리하고, 대화 상태를 유지.
3.
히스토리 삭제
•
불필요한 메시지를 삭제하여 토큰 사용량 감소.
•
두 가지 방법:
◦
수동 삭제: RemoveMessage를 사용하여 특정 메시지 삭제.
◦
노드 추가: 워크플로우에 삭제 노드를 추가하여 자동 삭제.
4.
히스토리 요약(Summarize)
•
대화 기록을 요약하여 중요한 정보만 유지.
•
요약된 내용을 SystemMessage로 추가하여 다음 대화에 활용.
•
히스토리 삭제 및 요약 구현
1.
수동 삭제
•
RemoveMessage 메서드를 사용하여 불필요한 메시지 삭제.
•
예: 마지막 메시지만 유지하고 이전 메시지 삭제.
2.
노드 추가를 통한 삭제
•
워크플로우에 삭제 노드를 추가하여 자동으로 메시지 삭제.
•
예: Delete 노드를 추가하여 특정 메시지 삭제 후 다음 단계로 이동.
3.
요약 노드 추가
•
Summarize 노드를 추가하여 대화 기록 요약.
•
요약된 내용을 SystemMessage로 저장하여 다음 대화에 활용.
4.
요약된 메시지 활용
•
요약된 내용을 LLM 호출 시 포함.
•
System Message로 요약된 내용을 전달하여 대화의 맥락 유지.
•
예제 시나리오
1.
이메일 초안 작성 및 수정
•
사용자가 이메일 초안을 요청.
•
초안 작성 후, 사용자가 수정 요청.
•
수정된 초안을 요약하여 대화 기록에 추가.
2.
불필요한 메시지 삭제
•
이전 대화 기록 중 불필요한 메시지를 삭제.
•
예: "이메일 초안을 작성해 주세요" 요청 이후, 초안 작성 완료 메시지만 유지.
3.
요약된 메시지 활용
•
요약된 대화 기록을 기반으로 다음 대화 진행.
•
예: "이전 초안을 수정해 주세요" 요청 시, 요약된 초안을 기반으로 수정.
3.6 Human-in-the-loop: 사람이 Agent와 소통하는 방법
•
Human-in-the-Loop 개념
◦
에이전트의 작업 흐름에 사람이 개입하여 효율성을 높이는 방법.
◦
사람이 에이전트의 작업을 검토하고, 필요 시 수정하거나 다음 단계를 결정.
◦
주요 활용 사례:
1.
LLM이 적절한 판단을 내렸을 때 그대로 진행.
2.
LLM이 적절한 도구를 선택했으나, 쿼리를 수정해야 할 때.
3.
LLM이 잘못된 도구를 선택했을 때 올바른 도구로 변경.
•
Human-in-the-Loop 구현 방식
◦
Interrupt: 사람이 개입하여 작업을 중단하고 검토.
◦
Command: 중단된 작업을 재개하거나 수정된 작업을 실행.
◦
Checkpointer: 중단된 지점을 기록하여 작업 재개 시 활용.
•
코드 구현
1.
Human Review Node 생성
•
에이전트의 작업을 검토하는 노드 추가.
•
마지막 메시지를 가져와 도구 호출 정보를 검토.
•
Interrupt를 통해 작업 중단 및 검토 메시지 표시.
2.
세 가지 주요 액션 구현
•
Action 1: LLM이 적절한 판단을 내렸을 때
◦
Interrupt 후 Command로 작업 재개.
◦
도구를 그대로 실행.
•
Action 2: 도구는 적절하지만 쿼리를 수정해야 할 때
◦
Interrupt 후 쿼리 수정.
◦
AI 메시지의 Tool Calls를 업데이트하여 수정된 쿼리 전달.
•
Action 3: 잘못된 도구를 선택했을 때
◦
Interrupt 후 도구 메시지를 수정.
◦
올바른 도구를 선택하도록 에이전트에 전달.
•
예제 시나리오
1.
LLM이 적절한 판단을 내린 경우
•
예: "논문 요약 요청" → Archive 도구 선택 → 그대로 실행.
•
Interrupt 후 Command로 작업 재개.
2.
쿼리 수정이 필요한 경우
•
예: "LLM Survey 논문 요약 요청" → Archive 도구 선택 → 쿼리를 "Large Language Models: A Survey"로 수정.
•
Interrupt 후 쿼리 수정 및 Command로 작업 재개.
3.
잘못된 도구를 선택한 경우
•
예: "LLM Survey 논문 요약 요청" → Archive 대신 DuckDuckGo Search로 변경.
•
Interrupt 후 도구 메시지 수정 및 Command로 작업 재개.
•
그래프 구조 변경
◦
Human Review Node를 추가하여 에이전트의 작업 흐름에 사람 개입 가능.
◦
Interrupt와 Command를 활용하여 작업 중단 및 재개.
◦
Checkpointer를 통해 중단된 지점 기록 및 재개 시 활용.
•
결과 및 장점
◦
사람이 에이전트의 작업을 검토하고 수정하여 정확도와 효율성 향상.
◦
잘못된 도구 선택이나 비효율적인 쿼리를 수정하여 최적의 결과 도출.
◦
Human-in-the-Loop를 통해 에이전트와의 상호작용 강화.
3.7 "찐" Multi-Agent System (feat. create_react_agent)
•
멀티 에이전트 시스템 개요
◦
멀티 에이전트는 여러 에이전트가 협력하여 복잡한 작업을 수행.
◦
주요 패턴:
1.
Single-Agent: 단일 에이전트와 도구로 구성된 기본 구조.
2.
Network: 에이전트 간 상호 연결을 통해 작업 수행.
3.
Supervisor: 모든 에이전트가 슈퍼바이저와만 통신하며, 최종 결정을 슈퍼바이저가 내림.
4.
Hierarchy: 각 에이전트가 개별 슈퍼바이저와 통신하며 계층적 구조를 형성.
5.
Custom: 개발자가 설정한 워크플로우에 따라 작업 수행.
•
Supervisor 패턴의 장점
◦
에이전트 간의 복잡한 상호작용을 단순화.
◦
슈퍼바이저가 최종 결정을 내리므로 작업 흐름이 명확.
◦
작업을 세분화하여 각 에이전트가 특정 역할에 집중.
•
멀티 에이전트 시스템 구현 과정
1.
에이전트 정의
•
Market Research Agent: Yahoo Finance News를 사용하여 시장 조사.
•
Stock Research Agent: Y-Finance를 사용하여 주식 데이터 조사.
•
Company Research Agent: Y-Finance를 사용하여 회사 재무 정보 및 SEC 문서 조사.
2.
Supervisor 정의
•
에이전트로부터 수집된 정보를 관리하고 최종 결정을 내림.
3.
그래프 빌더 생성
•
에이전트와 슈퍼바이저를 노드로 추가.
•
슈퍼바이저가 에이전트로부터 정보를 수집하고 최종 결과를 전달하도록 엣지 연결.
4.
Analyst 노드 추가
•
수집된 정보를 기반으로 최종 투자 결정을 내리는 역할.
•
슈퍼바이저에서 Analyst로 정보를 전달하고, Analyst가 최종 결과를 생성.
•
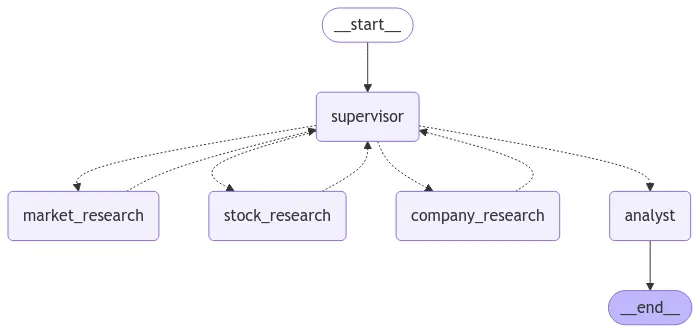
예제 시나리오
1.
질문: "Snowflake라는 회사에 투자할까요?"
•
Market Research Agent: 시장 뉴스 조사.
•
Stock Research Agent: 주식 데이터(종가, 시가 등) 조사.
•
Company Research Agent: 회사 재무 정보 및 SEC 문서 조사.
•
Supervisor: 에이전트로부터 수집된 정보를 Analyst에게 전달.
•
Analyst: 최종 투자 결정을 내림.
2.
결과:
•
장기적으로는 "보유" 추천.
•
단기적으로는 "매도" 추천.
•
중요 개념 및 팁
◦
React Agent: 도구를 선택하고 작업을 수행하는 "생각하는" 에이전트.
◦
Custom Tool: Y-Finance와 같은 외부 API를 활용하여 맞춤형 도구 생성.
◦
Prompt 최적화: 각 에이전트의 역할에 맞는 간결하고 명확한 프롬프트 작성.
◦
작업 세분화: 작업을 여러 에이전트로 나누어 효율성 및 정확도 향상.
◦
비용 절감: 작은 LLM 모델과 간단한 프롬프트를 사용하여 비용 절감.
3.8 커스텀 도구(tool)를 최대한 활용하는 방법
•
3.3 LangGraph에서 도구(tool) 활용 방법, 3.4 LangGraph 내장 도구(tool)를 활용해서 만드는 Agent 에서 본 것처럼 랭체인에서 제공하는 내장 도구(tool)들을 활용할 수도 있지만, 커스텀 도구(tool)도 활용 가능
•
함수를 작성하고 아래 작업을 통해 함수를 도구(tool)로 선언하면, LLM이 어떤 도구를 어떻게 활용할지 스스로 판단함
◦
@tool decorator추가
◦
tool로 활용되는 함수 이름 작성
◦
함수 argument의 변수명과 타입 작성
◦
함수 return 값의 타입 작성
◦
docstring을 활용한 주석 작성
•
node와 tool 비교
◦
Node는 항상 “state”를 args로 넣어줘야함
▪
state에 있는 값을 사용하던 안하던 무조건
◦
Node는 항상 state를 return함
◦
docstring은 강의 소스코드라서 추가한 것이고 필수는 아님

◦
tool은 진짜 함수처럼 작성
▪
arguments가 필요없다면 공란으로 비워도 가능
▪
state대신 함수의 실행 결과를 return함
▪
LLM의 도구사용을 위해 docstring을 필수로 작성해야함

4. Outro
4.1 Recap & Next Step
from IPython.display import Image, display
display(Image(graph.get_graph().draw_mermaid_png()))
Python
복사
4.1.1 기본 에이전트
•
기본 챗봇 형태의 에이전트
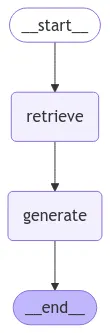
•
기본 RAG Pipeline 형태의 에이전트
4.1.2 LangGraph 공식문서 RAG 응용
•
Agentic RAG
•
Self RAG
•
Corrective RAG
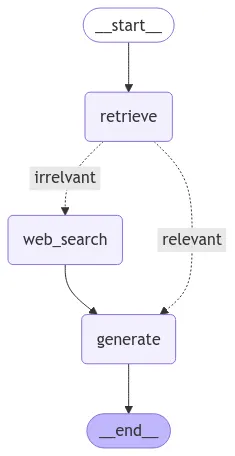
•
Adaptive RAG
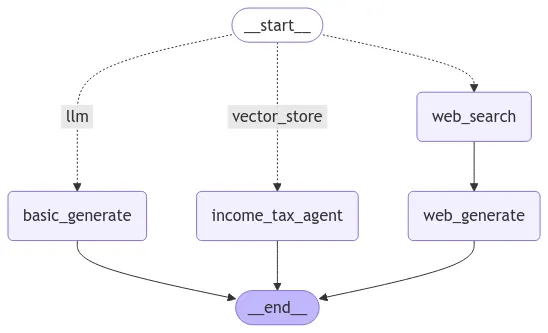
•
병렬처리 Workflow
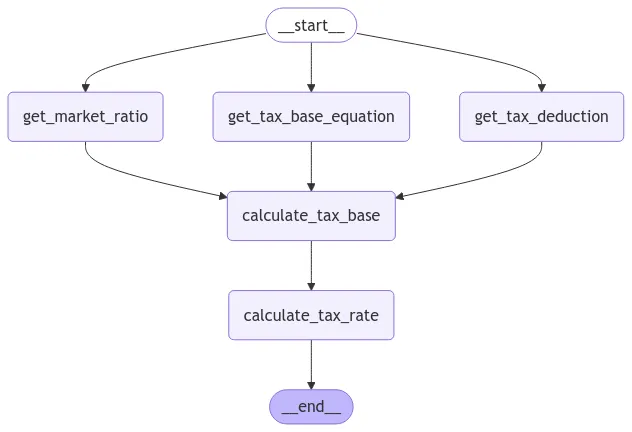
•
Multi-Agent Workflow
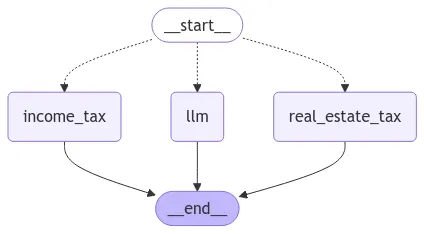
4.1.3 도구(tool) 활용
•
tool_conditions, create_react_agent
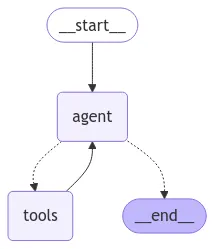
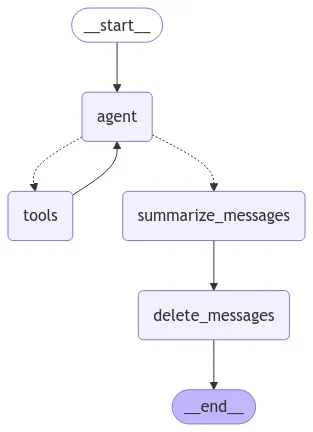
•
checkpointer를 활용한 히스토리 관리
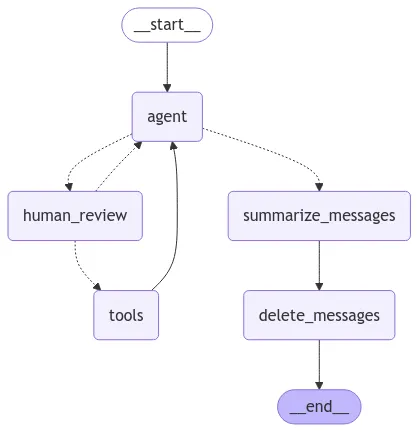
•
human-in-the-loop
•
Multi-Agent with Supervisor
4.2 안정적인 서비스 운영을 위해 필수인 LLM Evaluation
4.2.1 Deep Learning Model 개발
•
Deep Learning Model의 목적 설정
◦
Natural Language Processing(NLP)의 경우,
▪
텍스트 분류 → RNN
▪
언어 번역 → seq2seq
▪
질문 답변 → RoBERTa
▪
감정분석 → GRU
▪
음성인식 → wav2vec
▪
텍스트 생성 → Transformer
•
데이터셋 선정
◦
Train Set
▪
모델이 직접 학습하는 데이터
▪
가중치와 편향을 최적화하는 데 사용
▪
번역을 예시로 들어보면
•
최소 100만 쌍의 병렬 문장 (source-target pairs)이 필요
•
실용적인 수준의 성능을 위해서는 500만-1000만 쌍 정도 권장
•
고품질 번역을 위해서는 2000만 쌍 이상이 이상적
◦
Validation Set
▪
학습 중 모델의 성능을 평가하는 데이터
▪
하이퍼파라미터 튜닝에 활용
▪
과적합 여부를 확인하는 지표
◦
Test Set
▪
학습이 완료된 모델의 최종 성능을 평가하는 데이터
▪
한 번도 학습에 사용되지 않은 새로운 데이터
▪
실제 현장 적용 시의 성능을 예측하는 지표
4.2.2 LLM 활용 서비스 개발
•
LLM의 목적 → 텍스트 생성
◦
서비스를 만드는 것은 프롬프트를 작성해서 원하는 텍스트를 생성하게 하는 것
◦
직접 모델을 훈련하지 않음
▪
GPT, Claude, Mistral 등의 모델이 어떤 데이터를 활용해서 테스트 했는지 알 수 없음
▪
Output을 예측할 수 없음
•
데이터셋 선정
◦
Test Set을 설정해야함
◦
개발하고자하는 서비스에 맞는 Test Set
4.2.3 LLM Evaluation이란?
•
LLM이 주어진 작업에서 얼마나 정확하고 효울적으로 작동하는지 측정하는 과정
◦
GPT, Claude와 같은 언어 모델이 사용자 질문에 적절한 답변을 제공하는지
◦
모델의 응답이 논리적이고 일관성이 있는지
•
Evaluation을 통해 모델의 성능을 정량적/정성적으로 측정하여 개선이 필요한 부분을 파악할 수 있음
◦
프롬프트 개선에 특히 필수
◦
모델을 직접 개발하지 않고, 다양한 상용화 모델을 활용할 때 특히 중요함
4.2.4 Evaluation의 목적
•
품질 관리
•
문제 해결 및 개선
•
사용자 신뢰 확보
•
비용 효율성
•
법 / 윤리적 책임
5. Model Context Protocol(업데이트 예정)
5.1 MCP 무조건 써야 하나요?
5.1.1 MCP란?
•
Claude를 만든 Anthropic에서 공개한 AI Agent 개발용 프로토콜

•
웹개발의 REST API와 유사함
◦
MCP Client는 필요한 데이터를 MCP Server에 요청
◦
MCP Server는 데이터베이스(vector db, RDB, NoSQL), 도구, 프롬프트 등등을 MCP Client요청에 따라 전달
5.1.2 LangGraph에서 MCP활용하기
•
일반 AI Agent는 MCP Client와 소통

◦
LangGraph Agent의 경우 langchain-mcp-adapters 패키지 활용
•
•
단점
◦
MCP도 서버이기 때문에 추가 리소스, 인프라 필요
◦
관리포인트가 늘어나는 것은 맞는듯
5.2 커스텀 MCP 서버 개발방법
5.2.1 Claude 활용방법
•
MCP 공식문서에 자세히 나와있음
◦
하지만 이것도 코드만 제공하고, 어떻게 사용하는지는 별도의 절차가 필요함
◦
그래도 좋은 baseline을 제공
5.2.2 Python SDK 활용
•
1.x 버전의 공식 sdk:  python-sdk
python-sdk
•
다양한 언어 지원
◦
TypeScript, Java, Kotlin, C# 등
◦
메인은 TypeScript로 추정
▪
파이썬으로 작성한 서버를 로컬에서 올려서 inspector로 연결하면 node서버 로그가 확인됨
5.3 langchain-mcp-adpater를 활용한 MCP 도구 사용
•
MCP 통신을 위한 transport STDIO, Streamble HTTP
◦
초창기에는 SSE가 기본 transport였으나 deprecate되고 Streamble HTTP로 변경됨
[LEGACY]
5.3.1 공식문서의 MCP Client 활용방법 I (feat. MultiServerMCPClient)
•
5.3.2 공식문서의 MCP Client 활용방법 II (feat. ClientSession)
•
공식 GitHub 참고:  GitHubGitHub - langchain-ai/langchain-mcp-adapters
GitHubGitHub - langchain-ai/langchain-mcp-adapters
GitHubGitHub - langchain-ai/langchain-mcp-adapters5.4 공식문서에 없는 MCP Client 활용방법
•
LangGraph스럽게 MCP Client를 활용하는 방법
•
공식문서에서 제안하는 방식과 다르게 state 를 활용할 수 있음
